





karmada是华为开源的云原生多云容器编排平台,目标是让开发者像使用单个k8s集群一样使用多k8s云。它的第一个release(v0.1.0)出现在2020年12月,而正式发布则是在2021年4月25日,在深圳召开的华为开发者大会(HDC.Cloud)2021上。
karmada吸取了CNCF社区的Federation v1和v2(也称为kubefed)项目经验与教训,在保持原有k8s资源定义API不变的情况下,通过添加与分布式工作负载部署管理相关的一套新的API和控制面组件,方便用户将工作负载部署到多云环境中,实现扩容、高可用等目标。
官方网站:https://karmada.io/
代码地址:https://github.com/karmada-io/karmada
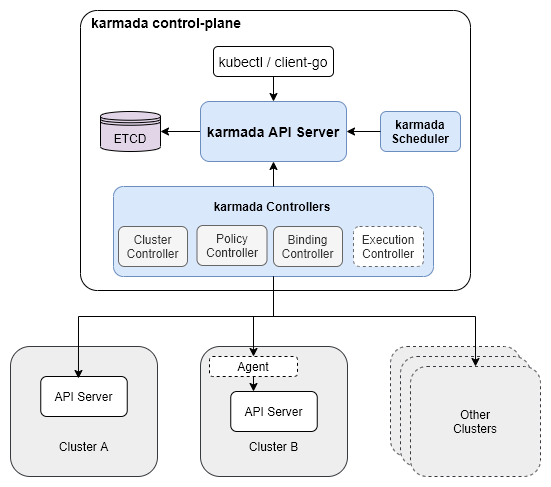
使用karmada管理的多云环境包含两类集群:
host集群:即由karmada控制面构成的集群,接受用户提交的工作负载部署需求,将之同步到member集群,并从member集群同步工作负载后续的运行状况。
member集群:由一个或多个k8s集群构成,负责运行用户提交的工作负载
架构图如下:
本文描述karmada的上手流程,使用的karmada版本为v0.7.0后的commit:c4835e1f,与8月发布的v0.8.0差了二十几个commit。
1. karmada安装
1.1. 安装docker
按照docker官网文档在本机安装docker,对debian来说流程如下:
安装基础工具
安装docker的gpg key:
安装docker源
安装docker
1.2. 安装简易k8s开发集群管理工具:kind
kind官网对其描述:kind is a tool for running local Kubernetes clusters using Docker container “nodes”. kind was primarily designed for testing Kubernetes itself, but may be used for local development or CI.
在本地已经安装好go (1.11以上) 和docker的情况下,执行下面指令安装kind:
GO111MODULE=on GOPROXY=goproxy.cn go get sigs.k8s.io/kind@v0.11.1
0.11.1是当前kind最新的release的,也是后续部署karmada过程中指定要用的版本
kind使用一个容器来模拟一个node,在容器内部使用systemd托管kubelet和containerd(不是docker),然后通过被托管的kubelet启动其他k8s组件,比如kube-apiserver、etcd、CNI等跑起来。
由于kind使用containerd而非docker作为容器运行时,要查看kind启动的k8s节点内部容器运行情况,需要使用containerd的cli客户端ctr。可以通过下面这条命令查看后续步骤中karmada调用kind启动的单节点k8s集群内部容器的运行情况:docker exec karmada-host-control-plane ctr --namespace k8s.io containers ls。
ctr的flag
--namespace不是k8s里的namespace,也不是linux内核支持的namespace,感兴趣的同学可以查看containerd的namespace相关概念
1.3. 启动本地k8s集群,安装karmada控制面
1.确保已经安装make、gcc工具
2.确保已经安装kubectl,可以参考官方文档采用手动安装或包管理器的方式安装
3.clone karmada源码: git clone https://github.com/karmada-io/karmada.git karmada-io/karmada
4.cd karmada-io/karmada
5.hack/local-up-karmada.sh,这里包含一系列步骤:
1)检查go、kind等工具是否已经存在
2)调用kind创建host k8s集群,集群版本默认为1.19.1,与karmada重用的k8s组件(kube-apiserver、kube-controllermanager)版本一致 。创建k8s集群需要的kindest/node:v1.19.1镜像较大,可以提前下载好,防止后续的local-up-karmada等待集群启动超时(默认5分钟)
3)build karmada控制面可执行文件及容器镜像,build结束后本地可以找到如下镜像:karmada-agent、karmada-webhook、karmada-scheduler、karmada-controller-manager
4)部署karmada控制面组件到host集群
5)创建CRD,也就是karmada自定义的多云工作负载API资源,包含:propgation policy,override policy,work,resource binding等
6)创建webhook
7)部署完成后,形成kubeconfig文件$HOME/kube/karmada.config,包含karmada-host和karmada-apiserver两个context,分别对应支撑karmada控制面运行的host集群,以及karmada控制面本身
注意:karmada还提供了remote-up-karmada.sh脚本,用以把一个现有的k8s集群加入联邦。感兴趣的读者可以阅读karmada项目的readme尝试
2. karmada控制面构成
部署karmada完成后,在切换到karmada-host context后,执行kubectl get po --all-namespaces可以得到已经部署的组件列表:
可以看到部署在两个namespace中的两个k8s控制面:
karmada-host context对应的控制面运行在kube-system namespace中,用来运行管理karmada控制面,是个由kind启动的标准的k8s管理节点。karmada-apiserver context对应的控制面运行在karmada-system namespace中,是karmada控制面,也就是karmada readme中提到的host集群。它由local-up-karmada.sh脚本部署到karmada-host集群中。该控制面重用了k8s的两个组件:kube-apiserver和kube-controllermanager以及etcd,其他3个为karmada组件,包括kamada-controller-manager、karmada-scheduler、karmada-webhook前一个k8s集群只是为了支撑karmada控制面的运行。所有后续集群联邦相关的操作,包括用karmadactl发出的member集群管理请求,以及用kubectl发出的工作负载管理请求都发往karmada控制面。这些请求中创建的API资源也保存在karmada控制面自身的etcd中(对应上面列表中的etcd-0 pod)。
需要注意的是,虽然karmada控制面重用了部分k8s组件,被重用的kube-controller-mamager通过启动flag限制其只运行namespace、garbagecollector、serviceaccount-token、serviceaccount这几个controller,所以当用户把Deployment等k8s标准资源提交给karmada apiserver时,它们只是被记录在karmada控制面的etcd中,并在后续同步到member集群中,这些Deployment资源并不会在karmada控制面管理的集群中发生reconcile(如创建pod)。
3. karmada使用
用户可以用karmadactl和kubectl两个cli使用karmada,其中:
1.karmadactl用来执行member集群的加入(joint)/离开(unjoin)、标志一个member集群不可调度(cordon)或解除不可调度的标志(uncordon)
2.kubectl用来向karmada集群提交标准的k8s资源请求,或由karmada定义的CR请求。用以管理karmada集群中的工作负载。
3.1 使用karmadactl管理member集群
hack/create-cluster.sh member1 $HOME/.kube/karmada.config创建新的集群member1执行kubectl config use-context karmada-apiserver切换到karmada控制面执行karmadactl join member1 --cluster-kubeconfig=$HOME/.kube/karmada.config以push的方式把member1加入karmada集群 注意:如果还没有编译过karmadactl可执行文件,可以在代码根目录执行make karmadactl
注意:karmada中的host集群和member集群之间的同步方式有push和pull两种,这里的上手过程采用push的方式,感兴趣的读者可以参考karmada的readme尝试pull同步方式
目前karmadactl没有list member集群的功能,对于已经加入的member集群,可以通过获取Cluster类型的CR实现:
kubectl get clusters
得到输出为:
NAME VERSION MODE READY AGE member1 v1.19.1 Push True 88s
上面的create-cluster.sh脚本默认创建最新版的k8s集群,为了避免再次拉下一个大镜像,可以修改create-cluster.sh脚本,为kind create cluster命令加上
--image="kindest/node:v1.19.1"参数
3.2 使用kubectl管理工作负载
karmada代码里自带一个nginx应用可以用来体验基于karmada的分布式工作负载管理:
1.执行kubectl config use-context karmada-apiserver切换到karmada控制面
2.执行kubectl create -f samples/nginx/deployment.yaml创建deployment资源
如前面所述,由于kamada控制面没有部署deployment controller,nginx不会在karmada控制面所在集群跑起来,而是仅仅保存在etcd里
这时候如果去member1集群查看pod资源的情况,可以发现nginx也没有在member1集群中运行起来
3.执行kubectl create -f samples/nginx/propagationpolicy.yaml,定义如下的propgation policy:
这个progation policy将之前部署的nginx deployment资源(由resourceSelectors指定)同步到member1集群(由placement指定)中。
这时不用切换到member1 context,对karmada控制面执行kubectl get deploy可以看到名叫nginx的deployment已经正常运行:
上述结果说明karmada有能力从member集群同步工作负载状态到host集群。作为验证,我们可以切换到member1集群,执行kubectl get po可以看到deployment对应的nginx pod已经在member1集群内正常运行:
4. 结尾并非结束
在Gartner的一份研究报告中,公有云用户有81%都采用了多云架构。近年来蓬勃发展的云原生社区对多云挑战给也几次给出自己的思考和解决方案,远有CNCF社区sig multicluster提出的Federation v1和v2,近有华为开源的karmada以及Red Hat开源的Open Cluster Management(OCM)。虽然尚未在API层面达成一致,但各开源项目都在吸取前人的经验教训的基础上优化演进。百家争鸣而非闭门造车,这正是开源的魅力所在。
后续我们会对karmada项目进行更为深入的分析。
 CpjJwWHV
CpjJwWHV
CpjJwWHV
CpjJwWHV





