




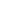

在讨论数据中间件是什么之前,我们先来讨论什么是中间件。
维基百科对中间件的定义:
中间件(英语:Middleware),又译中间件、中介层,是一类提供系统软件和应用软件之间连接、便于软件各部件之间的沟通的软件,应用软件可以借助中间件在不同的技术架构之间共享信息与资源。中间件位于客户机服务器的操作系统之上,管理着计算资源和网络通信。
常见的中间件有如下几类
· RPC框架
· 消息中间件
· 缓存服务
· 配置中心
· 任务调度
· 分布式事务
· 数据库
数据相关的中间件主要有:
数据库:数据库是数据存储的主要,由于需要写到缓存,包括关系型数据库(常见的mysql、oracal)、非关系型数据等(elasticsearch、hbase等)
缓存服务: 内存数据库,数据直接运行在内存中,加快访问速度,常见的比如redis、memcached
消息队列: 消息的传输过程中保存消息的容器。常见的比如rocketmq、kafka
数据中间件能做些什么?
尽管云原生开发存在诸多好处,但它同时也增加了复杂性。从本地系统到公共云,您可能会跨多种基础架构来部署应用。而应用架构本身也是多种多样。所以开发人员需要兼顾多种工具、语言和框架,同时还要竭力争取在更短的时间内以更低的成本完成更多工作,这无疑压力倍增。
为了应对这种复杂情况,企业纷纷选择了中间件来保持快速、经济高效的应用开发。中间件可以有力支持应用环境在高度分布式平台上平稳、一致地运行。
构建于此,而部署于彼。由于应用下层有中间件,所以跨环境也能稳定运行。
数据库
数据库可以直观的理解为存放数据的仓库,只不过这个仓库是在计算机的大容量存储器上,而且数据必须按照一定的格式存放,因为它不仅需要存放,而且要便于查找。
缓存服务
在计算机领域,缓存技术一般是指,用一个更快的存储设备存储一些经常用到的数据,供用户快速访问。用户不需要每次都与慢设备去做交互,因此可以提高访问效率。
分布式缓存就是指在分布式环境或系统下,把一些热门数据存储到离用户近、离应用近的位置,并尽量存储到更快的设备,以减少远程数据传输的延迟,让用户和应用可以很快访问到想要的数据。通常在应用访问数据库中间加一层缓存提高获取数据的速率。
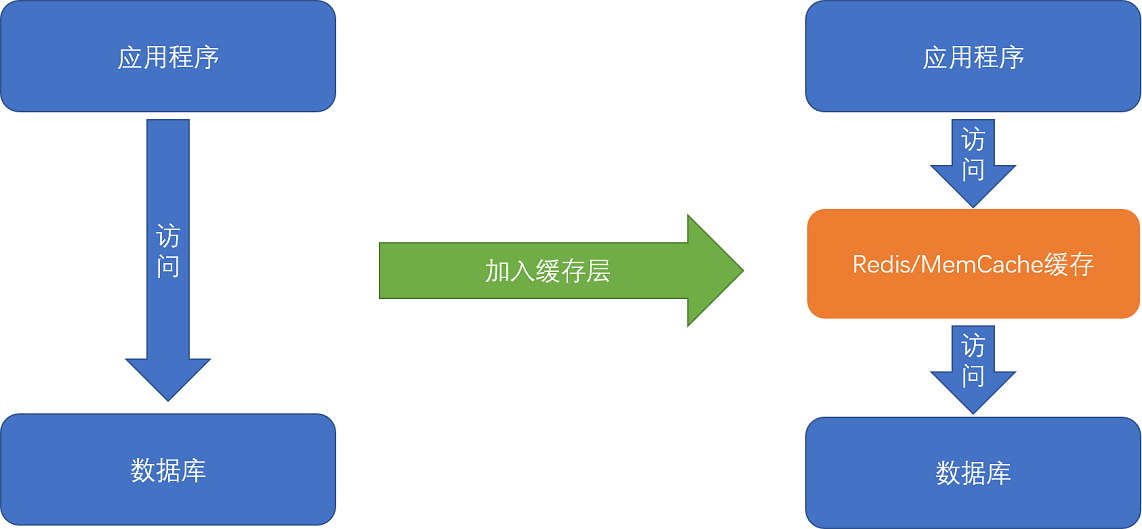
图:缓存服务的场景
消息队列
消息队列主要由以下作用:解耦,削峰,异步,其实还有一个作用是提高接收着性能。
· 解耦: 多个交互的应用程度可以独立变动,而无需太多考虑其他系统
· 削峰: 将流量高的时间平摊到不那么高的时候
· 异步: 异步处理不用阻塞当前线程来等待处理完成,而是允许后续操作

图:消息队列的场景
|
组件名称 |
作用 |
特点 |
|
数据库 |
数据存储,提供数据读写的功能 |
高安全性 |
|
缓存 |
主要提供数据库快速查询 |
高性能、高并发 |
|
消息队列 |
解耦业务、异步传输、流程削峰 |
高性能,扩展业务 |
如何建立数据中间件?
数据中间件本质是提高单机/分布式环境下 提交数据交互的速率和稳定性。
那么我们先来回顾一下操作系统原理,计算机系统中包含各类存储,从CPU寄存器到网络IO速率是依次递减。那么就需要在成本限定的前提下尽可能利用好高IO设备。
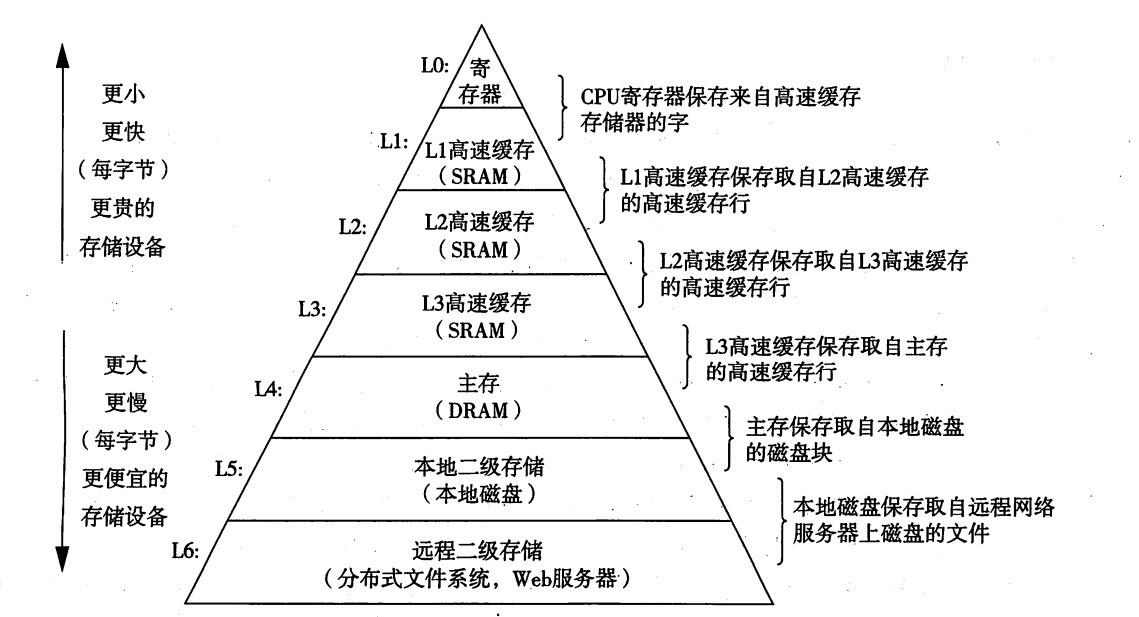
图:各类设备的IO速度
在物理资源不变的情况下,对于提高性能无非几种方法。
在非分布式环境下 通过数据结构优化/缓存/缓冲,分布式环境下数据复制+读写分离/数据分片
稳定性主要考虑的就是宕机/网络故障
数据存储(数据库)
数据库通常需要提供sql进行数据请求,由sql解析器进行语法解析,同时经过优化器进行语法优化,最后根据不同的存储引擎在缓存中读取数据。
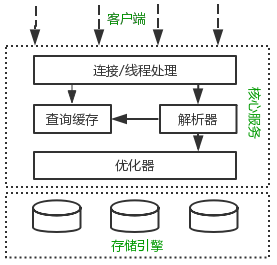
图:Mysql数据库的架构
数据库中用到了下面几种重要的原理:
索引
建立索引提高读取数据寻址的效率, 想想一下同样大小的文件夹(包含大量小文件)和压缩包,考虑的速率肯定是压缩包更快。前置是不连续地址,后者是连续地址。比如mysql主要通过b+树索引快速定位索引的内存位置并且获取数据。
内存缓存
虽然索引能够很大的提高速率,但是无法一次性将所有索引保存在内存中。 虽然linux内部提供page cache等方式提高,但是通常为了更加提高数据读写性能,通常自己另外实现一套应用级别的缓冲,比如mysql的buffer pool机制,通过索引在读数据时可以很大程度上减少磁盘IO的次数,大大提高了数据搜寻的速率。
其他
单机环境,再优化也会有性能瓶颈,同时无法应对宕机和网络故障问题,只能通过扩展解决。
常规的业务环境往往是读多写少,可以通过读写分离,大大提高读的性能,也能做到数据的冗余备份。
缓存服务
这里的缓存不是特应用的内部缓存,而是独立的缓存服务(也可以叫做内存数据库)。
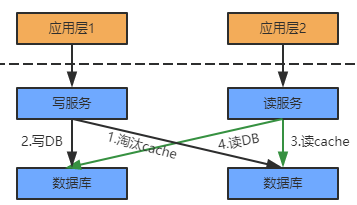
图:缓存与数据库的读写交互
写流程:
1. 要更新的数据是否在缓存中存在,若存在则直接将数据写入缓存,之后缓存数据由第三方缓存组件将其更新到DB.
2. 若缓存中不存在,则直接将结果写入DB,这种称之为写穿透
读流程:
1. 首先读缓存,如果缓存命中,则直接返回结果
2. 如果缓存未命中,则依赖第三方组件从DB 中加载数据到缓存中,然后将获取的结果返回。
内存缓存
这里说的内存缓存和数据库存在差异,由于数据库的安全性,需要经常落盘,那么就会带来很多问题;而缓存服务本身就作为内存数据库落盘不那么频繁。
当你访问数据库,存在大量的qps导致数据库跟不上性能,那么可以通过缓存解决,相对于数据库需要经常落盘,缓存大部分时间是无需落盘,内存IO的速度比磁盘IO快了很多,所以缓存往往是作为应用访问数据库的中间件层提高性能。
其他
由于缓存读多,很少使用数据库的事务,所以在数据分片实现是更加容易,扩展性也相对于数据库更加方便。
消息队列
消息队列是从数据结构中的队列(FIFO)中演变过来的,作为独立的队列,通过网络写入和读取数据。
异步处理:
有些业务不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们,例如短信通知、终端状态推送、App推送、用户注册等。
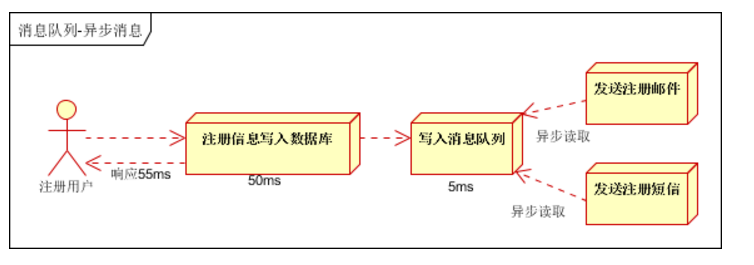
图:缓存异步读写
系统解耦:
降低工程间的强依赖程度,针对异构系统进行适配。在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。通过消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口,当应用发生变化时,可以独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。比如通讯上下行、终端异常监控、分布式事件中心。

图:缓存用作应用解耦
数据流处理:
分布式系统产生的海量数据流,如:业务日志、监控数据、用户行为等,针对这些数据流进行实时或批量采集汇总,然后进行大数据分析是当前互联网的必备技术,通过消息队列完成此类数据收集是最好的选择,比如日志服务、监控上报。
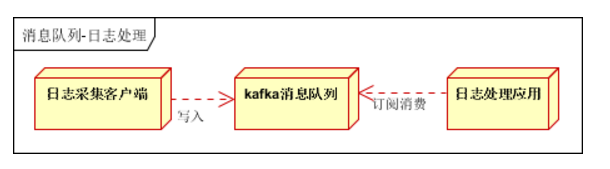
图:缓存用作数据流处理
数据中间件的发展趋势
1. 基于云原生环境的智能运维和扩展能力
对于中间件设施的开发和运维人员来说,中间件复杂的架构是难点。
目前云原生技术越来越成熟,可以充分利用云原生的声明式API,控制器模型扩展中间件,使其更加智能稳定。
比如目前开源的各类中间件operator的项目
https://kubernetes.io/zh/docs/concepts/extend-kubernetes/operator/
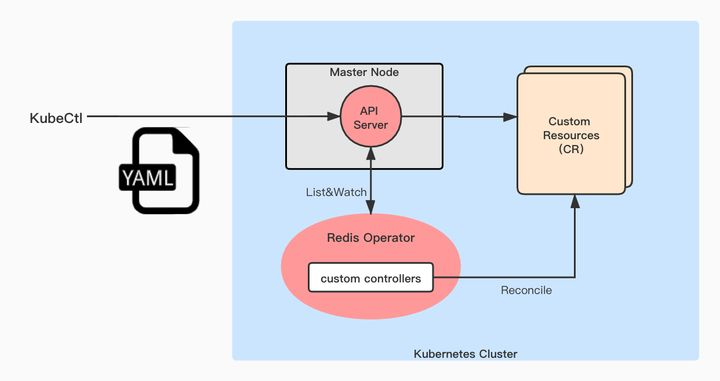
图:operator 原理
2. 统一的编程模型
对于应用的使用者来说,需要了解不同的中间件如何使用,同时需要考虑很多复杂的场景。编写高性能、可扩展且可靠的分布式应用程序很困难。可以使用同一的编程模型屏蔽底层的复杂场景。
Dapr项目是一个有趣的项目,它将事件驱动和参与者语义统一到一个简单、一致的编程模型中。它支持所有编程语言,没有框架锁定。您不会接触到低级原语,例如线程、并发控制、分区和缩放。相反,您可以通过使用您选择的熟悉的 Web 框架实现一个简单的 Web 服务器来编写代码。
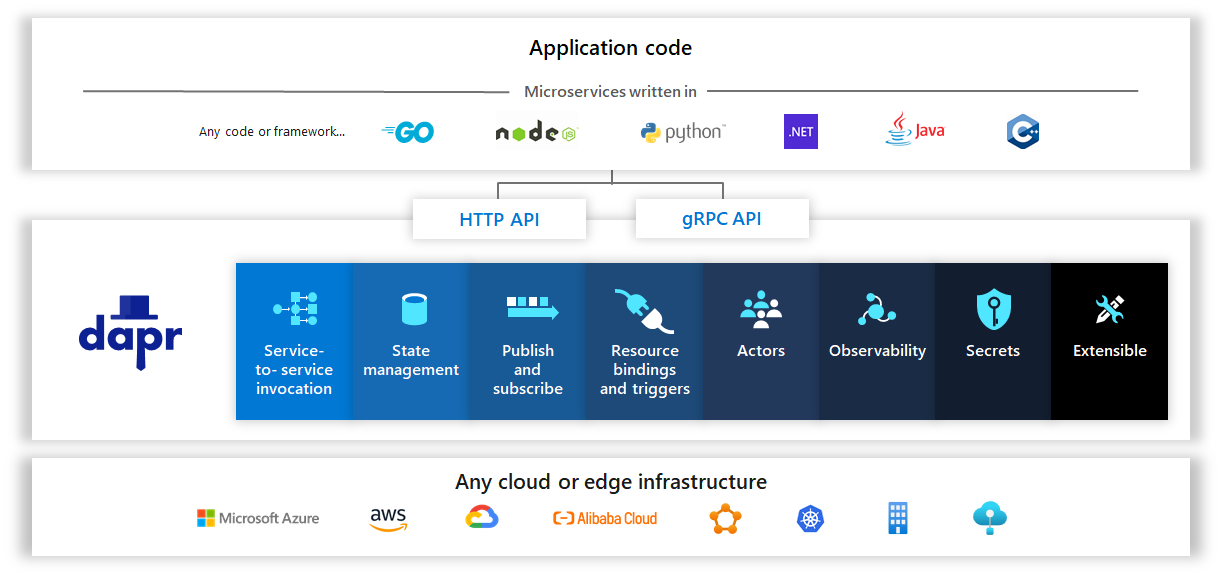
图:operator hub
 CpjJwWHV
CpjJwWHV
CpjJwWHV
CpjJwWHV





